DOM
On y est, c'est le moment de raccrocher les wagons, de se séparer de P5 et de faire du javascript pur pour manipuler des pages web.
Les points clefs qui nous débloque tout ça est la notion d'objets. Ce que l'on appelle le DOM (Document Object Model) est juste une façon pas nécessairement claire de dire que toute notre page web est répresentée sous forme d'un énorme objet document qui contient tous les éléments de la page en tant qu'objets.
Créez une page et collez-y cet HTML pour voir ce que ça vous met dans la console
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>Document</title>
</head>
<body>
<header>mon entete</header>
<main>le contenu</main>
<footer>le pied de page</footer>
<script>
console.log(document);
</script>
</body>
</html>
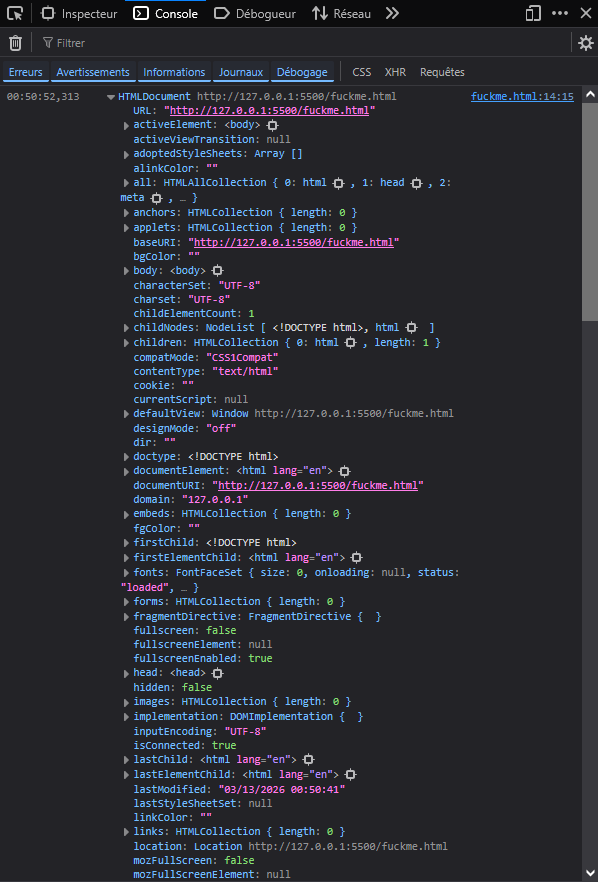
... ouais, c'est beaucoup plus gros que les objets avec lesquels ont a travaillé jusque là. C'est sympa d'explorer les différentes propriété qu'il possède et personnelement c'est comme ça que j'ai appris beaucoup de choses, mais ne vous inquietez pas, je vous montrerai ce qui peut vous servir, pas besoin de fouiller.
Pour le moment on pourra remarquer que document a une propriété children qui est un array d'éléments et chaque élément a un nodeName et ses propres children. Si je ne m'occupe pas des autre valeurs dans tout ces objets alors je peux représenter mon document comme ceci:
{
children:[
{
tagName:"HTML",
children:[
{
tagName:"HEAD",
children:[
{
tagName:"META",
children:[]
},{
tagName:"META",
children:[]
},{
tagName:"TITLE",
children:[]
}
]
},
{
tagName:"BODY"
children:[
{
tagName:"HEADER",
children:[]
},{
tagName:"MAIN",
children:[]
},{
tagName:"FOOTER",
children:[]
},{
tagName:"SCRIPT",
children:[]
}
]
}
]
}
]
}
Vous remarquerez que, de ce point de vu, ça ressemble énoremement à l'HTML. Et d'ailleurs j'imagine aussi que vous comprennez mieux l'intérêt d'indenter pour démarquer les niveaux d'imbrication.
C'est objets on un textContent qui contient le texte de l'élément.
Donc je pourrais écrire ceci comme javascript
// <html> <body> <main>
document.children[0].children[1].children[1].textContent = "coucou JS";
et quand vous ouvrirez la page le texte du <main> sera "le contenu" pendent très très peu de temps parce que le javascript va s'exécuter et son texte sera changé par le javascript.
Quel est l'intérêt?
On se rappelle qu'on pouvait exécuter une fonction quand on appuie sur une touche du clavier? Essayez avec ce javascript.
let count = 0;
const main = document.children[0].children[1].children[1];
function handleKey(event) {
if (event.key == "z") {
count = count + 1;
main.textContent = count;
}
}
window.addEventListener("keypress", handleKey);
Je sais, c'est pas grand chose, mais ça répond à la question, c'est ça tout l'intérêt, on peut maintenant programmer des comportements pour rendre la page intéractive (et utile, si on est fort en design).
Et c'est ce qu'on va voir pendant tout le reste du cours, comment manipuler notre HTML depuis le javascript.
document.querySelector()
children c'est bien sympa mais vous avez probablement compris que c'est nul. Déjà c'est très chiant à utiliser, mais surtout, qu'est ce qu'il se passe si je modifie mon HTML?
Si main n'est plus "le deuxième enfant du deuxième enfant du premier enfant du document" alors le code ci-dessus ne marchera plus, ou modifiera un autre élément de la page.
Une vrai bonne réponse est d'utiliser document.querySelector() qui permet de sélectionner un élément en fournissant un sélécteur CSS. Je peux réecrire ...
const main = document.children[0].children[1].children[1];
... en ...
const main = document.querySelector("main");
... pour récupérer l'objet correspondant à l'élément <main>.
Pour rappel le sélecteur c'est ce qui se met au début de la règle
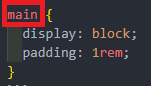
Donc je pourrais avoir une sélection plus complexe comme document.querySelector("body > main") par exemple.
document.querySelectorAll()
Ceci dit, la sélection complexe ce sera plus pour document.querySelectorAll() qui permet de récuperer un array d'éléments qui matchent (pas vraiment, mais pour nous c'est fonctionnelement pareil). À la différence de document.querySelector() tout court qui sélectionne le premier élément qui correspond au critère de sélection.
Petite démonstration :
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>Document</title>
</head>
<body>
<div>dehors</div>
<div>dehors</div>
<div>dehors</div>
<div>dehors</div>
<main>
<div>dedans</div>
<div>dedans</div>
<div>dedans</div>
<div>dedans</div>
</main>
<div>dehors</div>
<div>dehors</div>
<div>dehors</div>
<script>
const innerDivs = document.querySelectorAll("main div");
for (let i = 0; i < innerDivs.length; i = i + 1) {
innerDivs.textContent = i;
}
</script>
</body>
</html>
et effectivement, comme je l'ai dit un peu plus haut, on va passer le reste des chapitres à voir d'autres manières de modifier les éléments de la page.